[TOC]
CPU缓存
现在都是多核CPU,而每个核心都会有几级缓存:老的CPU会有2级缓存(L1,L2),新的CPU会有3级缓存(L1,L2,L3),如下图所示:
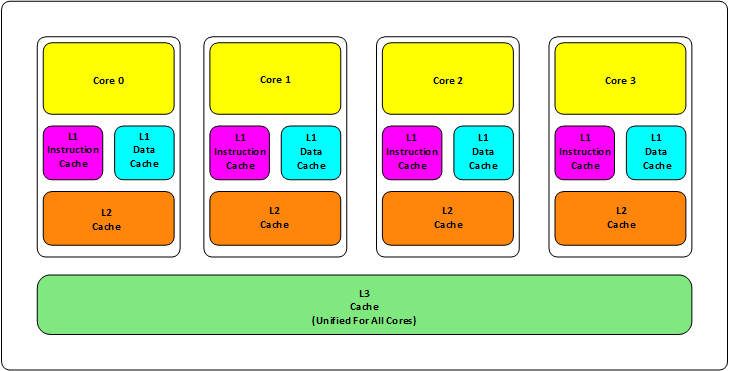
从上图来看,可以得出以下结论:
- L1缓存可以分成两种:指令缓存、数据缓存;L2、L3缓存不区分数据缓存和指令缓存;
- L1,L2缓存在每个CPU核心中,L3缓存是所有CPU核心共享的内存;
- 从L1到L3缓存,离CPU越来越远,速度也越来越慢,存储容量也越来越大;
- 缓存后面是内存,内存后面是硬盘,存储容量越来越大但是存取速度越来越慢;
我们可以从定量的角度来看下计算机中各个存储元件的速度以及容量级别到底是怎么样的:
- L1缓存的存取速度:4个CPU时钟周期,容量在KB级别;
- L2缓存的存取速度:11个CPU时钟周期,容量在KB级别;
- L3缓存的存取速度:39个CPU时钟周期,容量在MB级别;
- RAM内存的存取速度:107个CPU时钟周期,容量在GB级别;
当CPU核心需要数据时,数据流的流向是从内存 -> L3 -> L2 -> L1 -> CPU寄存器;
那为什么要设计这么多层缓存呢?主要原因是:
- 第一是访问速度:如果需要更大的容量就需要更多的晶体管,这样不仅会导致芯片体积增大,而且大量晶体管会导致速度下降;
- 第二是匹配RAM和cache的速度差异:多核技术中,数据需要在多个CPU核心中同步,而且缓存和RAM速度差异巨大,所以使用多级不同尺寸的缓存有利于提高整体性能;
引入多级缓存也会带来许多问题,这里指出两个比较重要的问题:
- 缓存命中率问题;
- 缓存更新一致性问题;
缓存命中率
首先来看缓存命中率问题:
这里先解释一些术语和概念方便之后的理解:
Cache Line:
对于CPU来说,并不会要求缓存一个字节一个字节的加载数据,这样很没有效率,而是一块一块的加载数据,所以这块数据单位就被称为Cache Line。一般来说Cache Line的大小为64Bytes,相当于16个32位整型,这也就是CPU从内存中获取数据的最小单位。
比如一个L1 Cache有32KB,那么32KB/64B = 512个Cache Line
CPU Associativity:
将内存的数据放到缓存中的过程称为CPU Associativity
地址关联算法:
Cache的数据放置策略决定了内存中的数据块会被拷贝到Cache的哪个位置,所以我们就需要一个地址关联算法,将内存中的数据映射到Cache中来;
一般来说有以下3种方法:
- 任何内存地址的数据都可以被缓存到任何一个Cache Line中;这种方法最灵活,但是在我们判断数据是否在Cache中时,需要进行O(n)复杂度变量整个Cache;
- 为了降低读数据时搜索Cache的时间复杂度,我们可以使用Hash的方法,比如:L1 Cache有512个Cache Line,那么我们可以:(内存地址%512)×64B,从而得到在Cache中存放这些数据的起始地址;但是这种方法要求对内存的数据访问比较平均,否则会出现大量的Hash冲突问题;
- 第三种方法是上面两种方法的一个折中,被称为N-Way关联,将连续的N个Cache Line设置为同一Way,查找过程就变成了先找到相关组,然后再在该组内找到相关Cache Line,这个过程也称为Set Associativity;
现在我们通过一个例子来说明N-Way关联的具体使用:
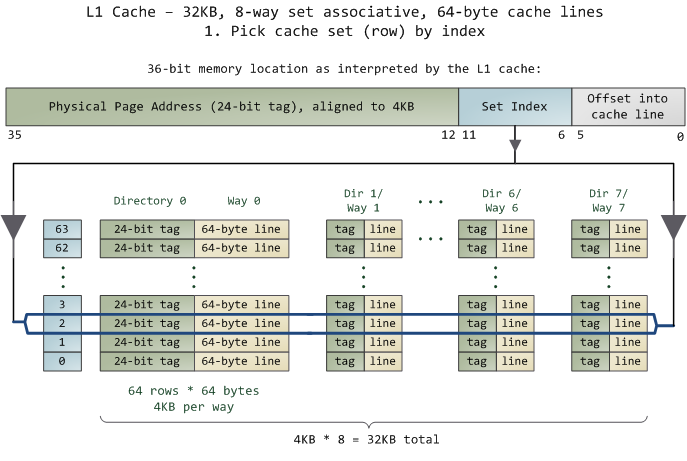
假设L1 Cache大小为32KB,8-Way关联,Cache Line为64Bytes,那么我们可以先得到以下结论:
L1 Cache一共有 32KB / 64B = 512条Cache Line
每一Way一共有 512 / 8 = 64 条Cache Line
每一Way一共有 64 × 64B = 4096Bytes = 4KB
为了方便在给定内存地址的情况下定位到对应的Cache Line,现在对Cache Line的前36bits做出如下定义:
Tag:Cache Line的前24bits,就是内存地址的前24位
Index:Tag后面连续6bits,刚好用于标识处于该Way的64个Cache Line中的哪个;
Offset:Index后面连续6bits,用于表示在Cache Line里面的偏移量,而Cache Line大小为64Bytes,
于是当有一个内存地址的时候,在8-Way关联的情况下该映射到L1 Cache的哪个部分呢?
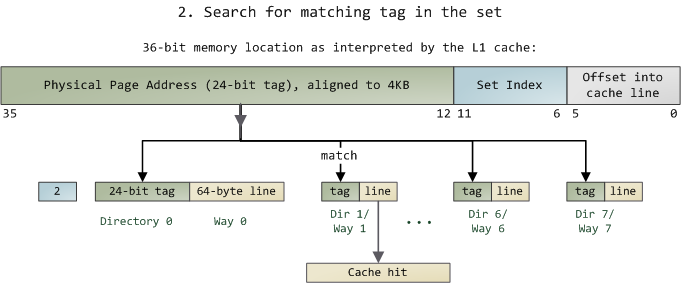
1.首先我们先拿出Index对应的6bits来,由于是8-Way所以找到对应的8个Cache Line;
2.然后我们在进行O(n)n=8的遍历,主要是匹配前24bits的tag,如果匹配成功那就说明命中,如果没有匹配到就说明该缓存中没有该数据,会依次向L2 Cache、L3 Cache、内存请求,;
这里我们假设匹配成功,那对于一个Cache Line来说,由于其前36bits用于处理内存地址相关信息,即2^36 = 64GB内存;
上述的步骤1,2对应下面的两幅图:
其实基于N-Way关联的Cache访问过程,类似于Java中获取HashMap中数据的过程:

缓存一致性问题
接下来我们来看一下缓存一致性的问题:
对于主流CPU来说,缓存的写策略基本就是两种:
Write back:写操作只写到cache上,然后再flush到内存上;Write Through:写操作同时写到cache和内存上;
为了获得更好的写性能,一般的CPU都是采用Write Back的策略,但是这样会导致一个问题:比如数据X在CPU某个核的缓存中更新了,那么其他核在使用X的时候如何感知这个更新呢?这就是缓存一致性问题,一般来说解决这个问题有两种方法:
- Directory协议:该方法需要一个集中式控制器(可以是主存储器控制器的一部分),需要维护一个记录各种本地缓存内容的全局状态信息。当单个CPU Cache发出读写请求时,这个集中式控制器会检查并发出必要命令,以在主存和CPU Cache之间或在CPU Cache之间进行数据同步和传输;
- Snoopy协议:该方法类似于一种数据通知的总线型技术,CPU Cache通过这个协议可以识别出其他Cache上的数据状态,如果有数据共享的话,可以通过广播机制将共享数据的状态通知给其他CPU Cache;
Directory协议是一个中心式的会有性能瓶颈,而且会增加系统设计复杂程度,Snoopy协议更像是微服务+消息通讯,所以现在基本都是使用Snoopy协议保障数据一致性的;